
Computer Vision
Completed
Stranger Sections: Segmenting Mysterious Objects Through the Microscope
$25,000
Completed 144 weeks ago
110 teams
Eager to get working? This challenge involves unsupervised segmentation of thin section images. There are 1000 unlabeled images in the dataset. Your job will be to provide a model that can accurately segment the blobs on the thin sections. You are free to explore any and all methods you see fit to effectively segment these images. There are two types of thin section images, plain light and ultraviolet light images. Ultraviolet light images are used to identify brown blobs that fluoresce a yellow or green color. Each image may contain a variety of blobs to segment. We have provided three examples of satisfactory labels in the `Data` discussion below to serve as a guide. Challenger's work will be evaluated by a panel of judges for accuracy of the label masks (70%), efficiency of the code (25%), and notebook organization (5%). In addition to the best overall model, challengers will be able to win prizes for honorable mentions.
Overview
Scale is one of the more interesting aspects of science. Biology investigates genomes and entire ecosystems. Physics spans quantum forces to gravitational waves from the Big Bang. Understanding all the different scales for a problem helps us better understand our natural world and how it is changing. For this challenge, we're asking you to investigate the micrometer scale of geosciences by examining thin sections of rocks and identifying their components.
This challenge aims to build a machine-learning solution to a problem often encountered by machine learning researchers; label scarcity. Challengers will receive 1000 unlabeled thin section images, and will need to provide a model that is able to correctly segment all blobs on each image.
The fun of this challenge is that there is no one correct way to complete this task. Challengers should focus on their strengths to build a model. If you are an expert with unsupervised clustering, maybe you use sklearn's kmeans to create segments with clustering. Maybe you want to test out Meta's SAM model, or better yet one of the offshoots like segmenteverygrain. Maybe your background is image processing and you spend most of your time building a pipeline to ingest and enhance the images prior to segmentation.
Since this challenge gives you the freedom to explore different paths, we will be awarding several different prizes for different accomplishments. A total prize pool of $25,000 dollars will be awarded, with smaller prizes available. Whatever approach you choose, all we ask is that the solution involves machine learning.
Data
As highlighted above, the dataset consists of 1000 unlabeled thin section images. Some of these images will be plain light images and others will be UV light. Some of the UV light images may also have a plain light pair. There will be various blobs on each thin section image that need to be segmented. Below are 3 examples showing how one might segment the images. The examples show the three types of blobs found on the images. As you'll see, there are potentially more segments on the image than what is currently segmented.
(A)

(B)

(C)
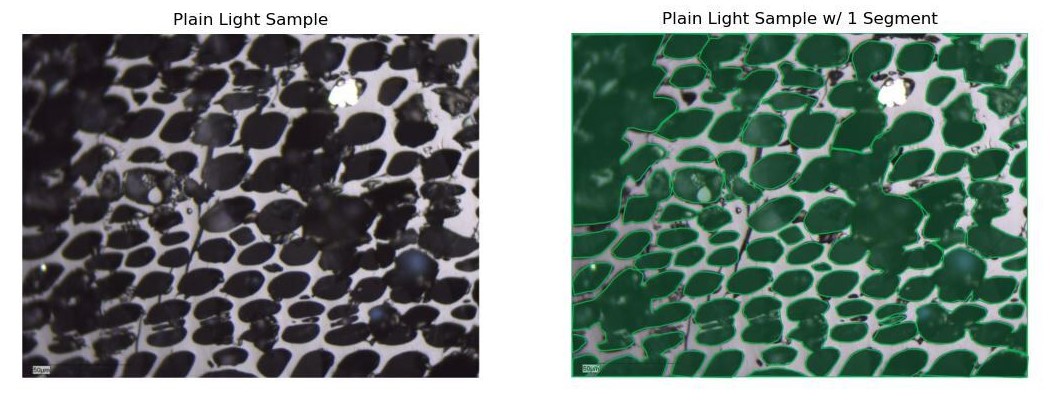
Figure 1. Thin section images with example segments. (A) UltraViolet Light (UV) thin section segmenting yellow blobs. (B) Plain light thin section segmenting shiny black/gray blobs. (C) Plain light thin section segmenting multiple black blobs.
Evaluation
Can you build a model to accurately segment all blobs in a thin section image? This is an unstructured competition where your task is to create a Notebook that best addresses the Evaluation criteria below. Since this is a subjective challenge, challengers will be judged by a panel of Xeek subject matter experts. Submissions should be submitted on the Stranger Sections challenge page and will be judged by Xeek based on how well they address:
Image Segments (70%)
How well are the images segmented?
If there are multiple blobs are they broken out into different segments?
Is the entire blob segmented?
If there are metrics available, did the author provide a way of assessing the performance and accuracy of their solution? - Silhouette Score, ARI, Loss Function
Code efficiency (25%)
What is the model runtime? *Note: If a clear winner cannot be determined visually, judges will look at code performance to determine a winner.*
Notebook Presentation (5%)
Does the notebook contain data visualizations that help to communicate the author’s main points?
Is the code documented in a way that makes it easy to understand and reproduce?
Were all external sources of data made public and cited appropriately?
A submission must contain:
A Jupyter Notebook with comments and model code in Python(>=3.6 is required)
A zip file with segment masks of the same size as the corresponding image. Masks files must be labeled in the format of “imagename_mask.npy.” Image masks will be provided as numpy arrays.
A requirements.txt file that contains the libraries used and their versions, as well as the Python version.
Xeek will take 1 hour to run the code. If the code cannot run in 1 hour, the challenger will be notified and given 24 hours to make edits. If no edits are made, the submission will be disqualified.
Only the most recent submission per category per user will be judged.
Prizes
There will be a total prize pool of $25,000 for this challenge. Participants will have the opportunity to win different categories of prizes based on the types of models they submit.
Best overall model ($12,000)
Honorable Mentions
Best segmentation model ($4,000)
Best clustering model ($4,000)
Best transfer learning model ($4,000)
Best visualizations/deployment ($1,000)