
Completed
Reflection Connection: Bringing New Algorithms to Old Data
$3,000
Completed 122 weeks ago
147 teams
One of a data scientist's superpowers is applying a solution developed for one discipline to another utterly separate discipline. The ingenuity and insights from researchers in different fields can help reframe a problem or create a breakthrough solution for others. For part four of the Encoded Reality Series of challenges, we ask you to take an algorithm developed for generic computer vision and apply it to geophysics.
Siamese Neural Networks (SNN) have shown great skill at one-shot learning collections of various images. This challenge asks you to train an algorithm to find similar-looking images of seismic data within a larger corpus using a limited training for eight categories. Your solution will need to match as many different features using these data. This challenge is experimental, so we are keen to see how different participants utilize this framework to build a solution.
Background
To non-geophysicists, seismic images are mysterious: lots of black-and-white squiggly lines stacked on one another (Figure 1). However, with more experience, different features in the seismic can be identified. These features represent common geology structures: a river channel, a salt pan, or a fault. Recognizing seismic features is no different from when a medical technician recognizes the difference between a heart valve or major artery on an echocardiogram. A geoscientist combines all these features into a hypothesis about how the Earth developed in the survey area. An algorithm that can identify parts of a seismic image will enable geoscientists to build more robust hypotheses and spend more time integrating other pieces of information into a comprehensive model of the Earth.

Figure 1. A seismic cross-line showing reflections between different rock units. This cross-line has many of the different classes in the challenge.
Challenge Structure
This challenge aims to test the limits of what classification algorithms can do with images of seismic data. You can win prizes for this challenge in multiple ways:
The best one-shot classification
The best freeform classification
The best calibrated confidence algorithm
Honorable mentions for novel ideas in classification
One-shot classification promises to get a model operational without needing abundance labels. In the starter notebook for this challenge, we introduce you to one such model, an SNN. You can further tune this SNN model or choose another one-shot framework that suits these data better.
For the freeform classification algorithm path, you can choose any classification algorithm for the eight categories. There are many classification algorithms out there, and we are keen to see what other ideas exist in the data science community for this problem. A part of this path, we will also award a prize for the model with the highest confidence score on the holdout data.
As this challenge format asks you to experiment, we will award five honorable mentions for interesting, novel attempts at either of these paths. You are eligible to win multiple prizes for this challenge.
The data for this challenge consists of images from eight classes for which you'll need to predict the best match. These classes have been hand-selected by the geoscience judging panel as representative of standard seismic features. These features record either changes in the geology (i.e., an ancient river channel) or how the seismic data was created (i.e., an error in processing). There are limited images in the training data (500), so strategically pick how you want to build your model.
Evaluation
To evaluate the performance of your solution, each participant will provide a JSON submission file containing a list of labels and confidence scores for the three best matching images from the image corpus for every image in the query set. This submission will be scored against an answer key, and the score will be reported on the Predictive Leaderboard. The evaluation metric used for scoring will be weighted accuracy:

The final score for all N query images is then calculated as follows:
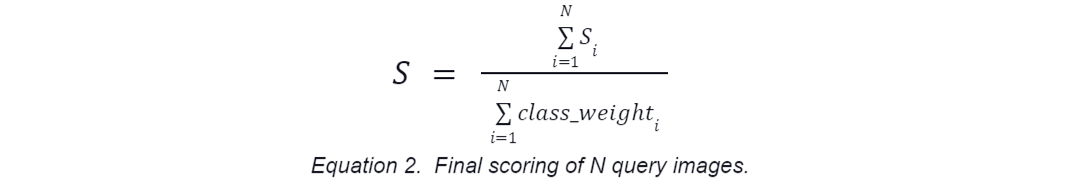
Images with higher confidence scores will have a higher impact on your final score. Instructions and the submission file generation code are provided at the bottom of the Starter Notebook. Note that the confidence score in the Starter Notebook can be used for either the freeform or one-shot classification tracks, but it’s not well-calibrated. You can also develop and use a confidence score for your design.
For the final evaluation, the submissions that reach a freeform classification score threshold of >0.5 on the Predictive Leaderboard will be invited to send Onward their fully reproducible code for evaluation against holdout data. For participants interested in the one-shot path, we’ll allow all participants to submit their code through the challenge page once the challenge is completed on March 22, 2024. Further instructions will be provided for one-shot submission at the close of the challenge.
For each of the two paths (freeform and one-shot), the final score on the holdout data will count for 75% of a participant's final score. Another 20% will be decided by a panel of judges who will be evaluating submissions on their creativity and effectiveness of the solution from a geophysical standpoint. The remaining 5% of the final score will assess submissions on the interpretability of their submitted Jupyter Notebook. The interpretability criterion focuses on the degree of documentation (i.e., docstrings and markdown), clearly stating variables, and reasonably following standard Python style guidelines. Please note that the more explanation you give for your solution, the better the panel will be able to repeat and understand your work and assess your model correctly.
A successful final submission must contain the following:
Jupyter Notebook with a clearly written pipeline.
Requirements.txt file that gives instructions on how to run training/inference for the submission
Any supplemental data or code to reproduce your results.
It must contain the libraries and their versions and the Python version (>=3.6).
See the Starter Notebook on the Data Tab for an example. The five honorable mentions will be awarded based on the assessment of the judge's panel on unique and/or effective models in classification architecture.
Timelines and Prizes
This challenge will open on December 20, 2023 and close on March 22, 2024 at 22:00 UTC.
There will be a total prize pool of $30,000 for this challenge. There will be different prize levels for challenges:
Best one-shot model ($14,000)
Best freeform classification model ($8,000)
Highest confidence for any model score ($3,000)
Five honorable mentions ($1,000)