
Sandbox
Completed
Identify and Extract Axes Values
Completed 202 weeks ago
100 teams
A lot of good data is trapped in old crossplots and graphs when they are archived. Pulling these data back out is a hurdle many disciplines face when bringing in legacy data to solve current-day problems. Manually capturing these data is not practical, but luckily we have algorithms. Machine learning techniques have advanced substantially in recent years to rescue these trapped data. For this challenge, we want you to solve a specific part of this problem-scape: extract information from the axes of crossplots.
This challenge is the first in a series targeting retrieving data from documents. Be on the lookout for more small challenges that target different parts of this much-needed workflow for any technical discipline.
Data and Labels
The data for this challenge are images of crossplots with two axes. The crossplots have a variety of sizes, formats, and orientations. The targets for extraction on both x and y axes are: minimum value, maximum value, and interval (tick) labels. An example of an image and the corresponding answer are shown below in Figure 1 and Table 1. Note that the x_axis_ticks and y_axix_ticks are bracketed strings of numbers with spaces as delimiters.
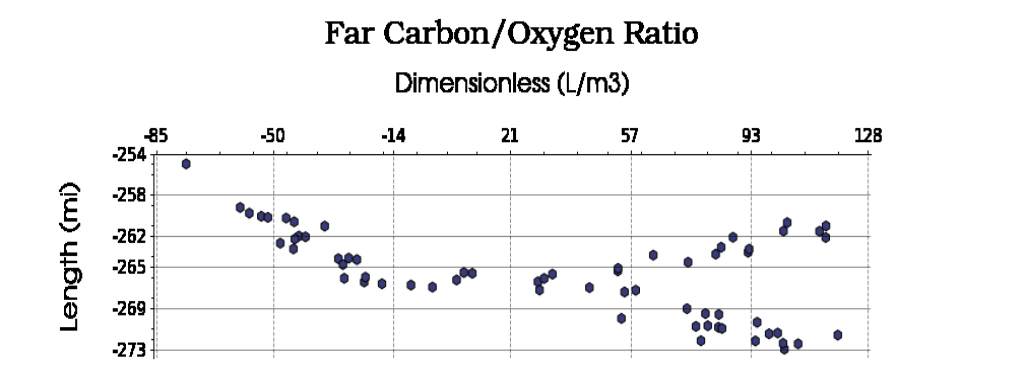
Figure 1: Example crossplot for this challenge.

Table 1: Correct answer for the crossplot in Figure 1.
Evaluation
During the challenge, a quantitative score will be used to populate the Predictive Leaderboard. Contestants will submit a CSV as described in the Starter Notebook, containing the six target features: x-axis min, x-axis max, x-axis ticks, y-axis min, y-axis max, and y-axis ticks. Submissions will be scored against the test answer key using root mean squared error. A lower score is considered more successful. Contestants can submit up to 5 CSV predictions per day.
At the end of the challenge, Xeek will request the models from the top 10 submissions for review by a panel of judges. A submission must contain a Jupyter Notebook, a requirements.txt, and any additional parameters a contestant has generated. The requirements.txt should describe the environment used to generate the model. It needs to contain the libraries and their versions and the Python version (>=3.6 is preferred). See the Starter Notebook on the Data Tab for an example.
The judges will score the top 10 submissions on accuracy and interpretability. The accuracy of the submission counts for 90% of the final score. Accuracy will be determined using the same scoring algorithm described above for the Predictive Leaderboard. The top 20% of scores will receive full points (90). Other submissions will receive points based on how closely they were to the top performing submissions.
The interpretability metric counts for 10% of the final score. This qualitative metric focuses on the degree of documentation, clearly stating variables for models, and using doc strings and markdown. Submissions with exceptional interpretability will receive full points (10). Other submissions will receive points based on the level to which they meet the criteria.