
Artificial Intelligence
Computer Vision
Segmentation
Transformers
Classification
Data Science
Supervised Learning
Completed
Core Values: A Geological Quest
$30,000
Completed 74 weeks ago
303 teams
Overview
You're on a mission to uncover the hidden secrets of sedimentary core photos, and we need your expertise. In this challenge, you'll be tasked with building a computer vision model that can segment sedimentary facies from core photos, processing at an incredible pace. Your goal is to create a model and pipeline that can identify and categorize these facies, making it easier for geologists to analyze the underlying geological structure. If you succeed in building a robust core segmentation model, you'll find some treasure along the way. But that's not all - your work will contribute to a better understanding of the Earth's geological history. Your model will be used to help geologists unravel the secrets of the earth.
Background
Sedimentary facies are patterns or characteristics of sedimentary rocks that help geologists grasp the history and environment in which they were formed. These facies can be used to infer information about the regional tectonic setting, sedimentary processes, and reservoir characteristics. Examples of common sedimentary facies include:
Sandstones with cross-bedding or horizontally stratified facies, which can indicate a high-energy depositional environment

Limestones with bioturbation or homogenization, which can suggest a low-energy depositional environment

Shales with folds and fractures, which can provide clues about the tectonic stress field and deformation history

A core sample is a small, cylindrical section of sedimentary rock extracted from the subsurface using a coring device. A single core sample is typically 1-50 inches (2.5-127 cm) in length and varies in diameter, ranging from 1/4 inch to 6 inches (6-152 mm). Full cores can range in length from just a few inches to hundreds of meters, providing valuable insights into the subsurface geology and composition. Core samples are used to gain a better understanding of the underlying Earth's structure, identify patterns and relationships between different rock layers, and inform decision-making in geological research.
A core photo is a high-resolution digital image of the core sample after the sample has been cut in half. The photo documents various characteristics of the rock, such as texture, color, and layering patterns. Core photos are often used to analyze the rock's properties and provide a visual representation of the subsurface geology.

Figure 1. Example of a core photo with a single section of core and associated segmented image.
Together, core samples and photos provide valuable information for geological research, exploration, and decision-making. By analyzing the characteristics of the core sample and its photo, scientists can better understand the rock's composition, structure, and underlying geological processes, ultimately informing decisions on research priorities, resource allocation, and environmental management.
In the energy industry, accurately identifying and segmenting sedimentary core photos is critical for understanding the underlying geological history. By segmenting core photos, you'll be helping to:
Identify prehistoric environments the sediments were deposited in before becoming rocks
Find similar and different types of sedimentary rocks across large areas
Increase efficiency by providing geologists with high-quality data for analysis
Evaluation
The image-wise macro-averaged Dice score is used to evaluate the performance of the multi-class segmentation task in this challenge. This metric measures the similarity between the predicted segmentation masks and the ground truth masks for each class, averaged across all images in the test dataset. The image-wise macro-averaged Dice score is calculated in three steps as outlined below:
Dice Score for Each Class: For each image, the Dice score is calculated for each class. The Dice score for a single class is given by:
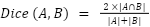
where (A) is the set of pixels in the predicted mask for the class, and (B) is the set of pixels in the ground truth mask for the same class.
Macro-Averaging: For each image, the Dice scores for all classes in that image are calculated and then are averaged to get the image-wise Dice score for that image. This ensures that each class contributes equally to the final score, regardless of its frequency. This process is repeated for each image in the dataset to obtain a single image-wise Dice score for each image.
Image-wise Averaging: Finally, the image-wise Dice scores are averaged across all images in the test dataset to obtain the Image-wise Macro-Averaged Dice score.
This metric provides a balanced evaluation by considering the performance across all classes and images, making it suitable for multi-class segmentation tasks.
To calculate your predictive leaderboard score based on the above-mentioned Dice metric, your submission file should be an .npz file containing 70 arrays (for the 70 samples in the test dataset). Each array's name should be a string in the format <sample_id>_lab, where <sample_id> corresponds to the sample IDs in the test dataset, ranging from 1 to 70. For example, for the test file 55_img.png with dimensions (287 × 1267), your .npz submission file should include an item named 55_lab with a label mask array of size (287 × 1267) as its value. Ensure that the data type for all predicted mask arrays is numpy.uint8. Your .npz submission file must contain exactly 70 items, representing predictions for all 70 test images.
For detailed explanations and helper functions related to the scoring algorithm and metric, as well as the submission format, please refer to the provided starter notebook. To further assist you, a sample submission file is available under the data tab, which will help you understand the required submission format.
Final Evaluation
For the Final Evaluation, the top submissions on the Predictive Leaderboard will be invited to send ThinkOnward Challenges their fully reproducible Python code to be reviewed by a panel of judges. The judges will run a submitted algorithm on up to an AWS SageMaker g5.12xlarge instance, and inference must run within 30 minutes for 81 images with similar distributions as the test dataset. The Dice score metric used for the Predictive Leaderboard will be used to score final submissions on an unseen hold out dataset. The score on this hold out dataset will determine 90% of your final score. The remaining 10% of the final score will assess submissions on the interpretability of their submitted Jupyter Notebook. The interpretability criterion focuses on the degree of documentation (i.e., docstrings and markdown), clearly stating variables, and reasonably following standard Python style guidelines. For our recommendations on what we are looking for on interpretability see our example GitHub repository (link) or check out our webinar on Top Tips for Succeeding in Data Science Challenges (link). Additionally, the Starter Notebook contains important points, guidelines, and requirements to help you understand what we are looking for in terms of interpretability.
A successful final submission must contain the following:
Jupyter Notebook: Your notebook will be written in Python and clearly outline the steps in your pipeline
Requirements.txt file: This file will provide all required packages we need to run the training and inference for your submission
Supplemental data or code: Include any additional data, scripts, or code that are necessary to accurately reproduce your results
Model Checkpoints (If applicable): Include model checkpoints created during training so we can replicate your results
Software License: An open-source license to accompany your code
Your submission must contain the libraries and their versions and the Python version (>=3.10). See the Starter Notebook on the Data Tab for an example.
Timelines and Prizes
Challenge will open on 18 December 2024 and close at 23:00 UTC 14 February 2025. Winners will be announced on 21 March 2025.
The main prize pool will have prizes awarded for the first ($10,000), second ($6,000), and third ($4,000) in the final evaluation. There will be five $2,000 honorable mentions for valid submissions that include (1) fastest GPU inference, (2) fastest CPU inference, (3) best custom model that does not use a highly abstracted API, (4) most innovative use of unlabeled data, (5) best documentation.